
Setting up your own SPARQL endpoint for Freebase (with a Java client)
Originally published July 5, 2014
SINDICETECH has done a great job configuring the RDF data dumps from Freebase and making them available as preconfigured images for both Google Cloud and AWS. You can read their documentation here.
I used SINDICETECH's AMI for Amazon Web Services and getting an EC2 instance set up was very simple (about 15 minutes, including the starup time for Virtuoso.). Good job SINDICETECH, and the people at Google and OPENLINK (helped tune Virtuoso) for making this happen! The directions called for using a small EC2 instance but since I will likely only be running my instance occasionally (as needed) I chose a medium instance, hopefully to make my queries run faster.
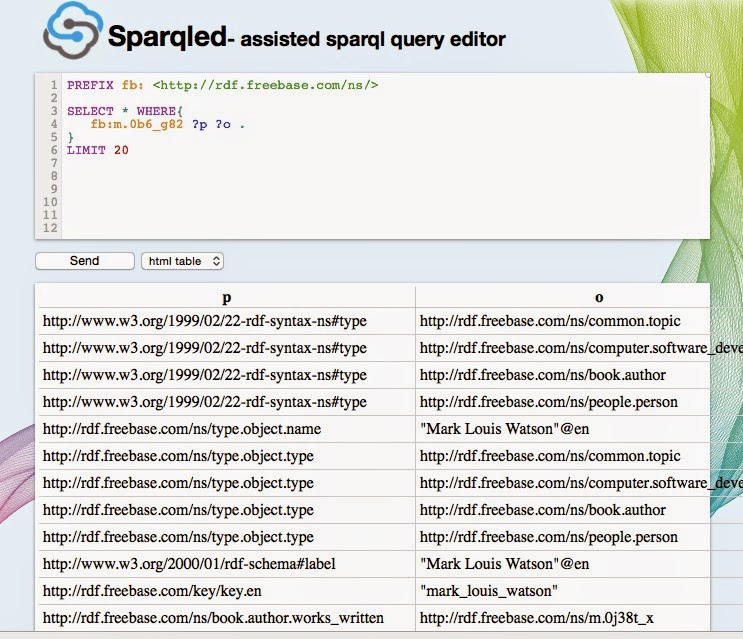
If you are used to using Freebase data, the conversion to the rdf.freebase.com/ns/ namespace is easy enough to understand. The easiest way to start exploring the data is to use the SPARQL web interface (see a screen shot at the end of this post). You can also use SPARQL libraries for your favorite languages and programmatically hit the SPARQL endpoint that you have set up on AWS or the Google Cloud. The MID on Freebase that represent me is /m/0b6_g82 and the following Java code runs a SPARQL query matching that MID as the subject:
package kb;
import com.hp.hpl.jena.query.*;
public class FreebaseSparqlTest1 {
public static void main(String[] args) {
String sparqlQueryString1=
"PREFIX fb: <http://rdf.freebase.com/ns/>\n" +
"\n" +
"SELECT * WHERE{\n" +
" fb:m.0b6_g82 ?p ?o .\n" +
"}\n" +
"LIMIT 20";
Query query = QueryFactory.create(sparqlQueryString1);
QueryExecution qexec =
QueryExecutionFactory.sparqlService("http://YOUR_IP_ADDRESS_HERE/sparql", query);
ResultSet results = qexec.execSelect();
while (results.hasNext()) {
QuerySolution sol = results.nextSolution();
System.out.println(sol.get("p") + "\t" + sol.get("o"));
}
qexec.close() ;
}
}
The following screenshot show the interactive SPARQL query web app:
I have been using the DBPedia SPARQL endpoint a lot recently. The reliability of this endpoint has improved dramatically but I would still like to also run my own instance. I set up DBPedia on a large memory server for a customer a few years ago - not a difficult process but it takes time.

Comments
Post a Comment